|
Qorus Integration Engine® Enterprise Edition 7.0.7_prod
|
|
Qorus Integration Engine® Enterprise Edition 7.0.7_prod
|
Back to the System Reference Manual Table of Contents
Managing workflows represents the primary functionality of the Qorus system. All information pertaining to workflows is stored in the Qorus database, from workflow metadata, to workflow logic, to the actual workflow data and states.
Qorus workflows are made up of several objects. Workflow metadata is stored in the WORKFLOWS table, and the parent table for workflow order data instance information is the WORKFLOW_INSTANCE table.
Important workflow attributes are depicted in the following graphic.
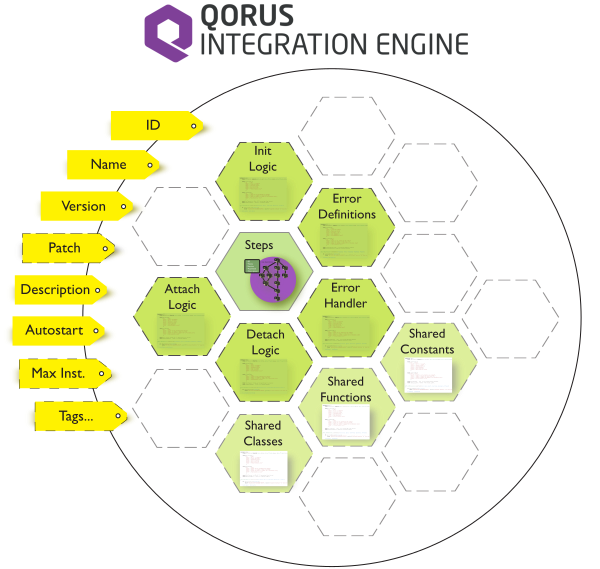
Workflow attributes are described in more detailed in the following table (for all workflow attributes, see Workflow Definition File).
Workflow Attributes (table: WORKFLOWS)
| Attribute | Mand? | Description |
workflowid | Y | The unique ID of the workflow; no two workflows can have the same ID (primary key for the table) |
| name | Y | The workflow's name |
| version | Y | The workflow's version |
patch | N | A string giving the patchlevel of the workflow's configuration. Note that the patch string is not used to differentiate different versions of this object. Objects have unique names and versions, but the patch string is used to track updated configurations of an object where updating the version number is not desirable. |
| description | Y | The description of the workflow |
| autostart | Y | The number of workflow execution instances to be started automatically |
| max_instances | Y | The maximum number of workflow execution instances that can be started concurrently (must be >= autostart) |
| attach logic | N | This logic will be executed each time Qorus starts to work on (i.e. "attaches to") a workflow order data instance |
| detach logic | N | This logic that will be executed each time Qorus stops working on (i.e. "detaches from" or "releases") a workflow order data instance |
| onetimeinit logic | N | This code will be executed once each time a workflow execution instance |
starts
deprecated | N | This flag indicates whether or not the workflow will be displayed in the web UI and can be started |
| Steps | Y | A list of steps and step dependencies; found in the table: WORKFLOW_STEPS |
| Segments | Y | A list of segments and segment dependencies, found in tables: SEGMENT_DEPENDENCIES, SEGMENT_STEPS |
| Tags | N | A list of user-defined tags for the workflow, stored in the WORKFLOW_TAGS table |
| Library Objects | N | A set of functions, classes, and constants that will be loaded into the workflow's program space; defined in table: WORKFLOW_LIB |
| Keys | N | A set of keys for searching workflow order data instances. Only key names in this list can be used to tag workflow order data instances for searching. Found in table: WORKFLOW_KEYS |
| Options | N | A set of valid options and option values for a workflow; defined in table: WORKFLOW_OPTIONS |
Each workflow is made up of one or more steps and the step dependencies.
Step metadata can be graphically depicted as follows.
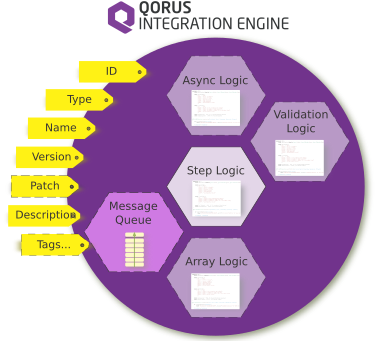
Steps have attributes as defined in the following table (see Step Definitions for all attributes).
Step Attributes (Table: STEPS)
| Attribute | Mand? | Description |
stepid | Y | The unique ID of the step; no two steps can have the same ID (also this is the primary key for the table) |
steptype | Y | see Step Types for valid step types |
| name | Y | The step's name |
| version | Y | The step's version; the name and version uniquely identify the step and correspond to one step ID |
| patch | N | A string giving the patchlevel of the step's configuration. Note that the patch string is not used to differentiate different versions of this object. Objects have unique names and versions, but the patch string is used to track updated configurations of an object where updating the version number is not desirable. |
| arraytype | Y | Defines the step as an array step or not; see Step Array Attribute Values for valid values |
| source | N | The source code to the step |
| queueid | Y/N* | * Mandatory for steps of type OMQ::ExecAsync (asynchronous steps); must not be present for other step types; foreign key to QUEUES |
| workflow_event_typeid | Y/N* | * Mandatory for steps of type OMQ::ExecEvent (workflow synchronization event steps), must not be present for any other step type; foreign key to WORKFLOW_EVENT_TYPES |
| Tags | N | A list of user-defined tags for the step, stored in the STEP_TAGS table |
Segments are a groups of steps separated by an asynchronous (type OMQ::ExecAsync), a workflow synchronization event step (type OMQ::ExecEvent), or a subworkflow step (type OMQ::ExecSubWorkflow). If a workflow has no asynchronous steps, no synchronization event steps, and no subworkflow steps, then the workflow will have only one segment (with segment ID 0).
Segments are executed semi-independently of one another; each segment has it's own resources and threads dedicated to processing only that segment. In this way, the Qorus Integration Engine® can pipeline data processing in the most efficient way possible while providing a very easy-to-use system construct to the programmer.
Segments have attributes as defined in the following table.
Segment Attributes
| Attribute | Mand? | Description |
workflowid | Y | The ID of the workflow the segment belongs to; foreign key to WORKFLOWS |
segmentid | Y | The ID of the segment, unique within the workflow only. Segment IDs in each workflow start with 0. |
| Steps | Y | List of steps in the segment with their dependencies, defined in SEGMENT_STEPS |
Workflow metadata (workflow configuration information) is loaded on demand into Qorus' workflow cache. If a workflow is updated, or dependent functions, etc are updated in the database, then, in order for the changes to take effect, the cached version of the workflow must be deleted so that the new version will be automatically loaded into Qorus' workflow cache.
The cached version of a workflow can be deleted with system REST APIs like PUT /api/latest/workflows/{id_or_name}?action=reset or the omq.system.reset-workflow() RPC API method.
When a cached workflow configuration is deleted, the system event WORKFLOW_CACHE_RESET is raised.
NORMAL (OMQ::WM_Normal) or RECOVERY (OMQ::WM_Recovery) mode will be automatically updated with the newer configuration when the cached version is deleted (for example, by calling PUT /api/latest/workflows?action=resetAll or omq.system.reset-all-workflows()). When this happens, the workflow execution instance does a partial stop, refreshes the configuration, and then restarts. It is not necessary to stop and start a workflow execution instance manually when workflow configurations are updated.Workflow order data instances represent order data to be processed by workflows; they are instantiations of Workflow Metadata, and they have attributes as defined in the following table.
Workflow Order Data Instance Attributes (tables: WORKFLOW_INSTANCE and ORDER_INSTANCE)
| Attribute | Description |
workflow_instance.workflow_instanceid | The unique ID of the workflow order data instance; no two workflow order data instances can have the same ID (this is the primary key for both these tables) |
workflow_instance.workflowid | Identifies the workflow the order data belongs to or is processed by. |
workflow_instance.workflowstatus | Indicates the status of the workflow order data instance. See Workflow, Segment, and Step Status Descriptions for more information |
workflow_instance.custom_status | This is an optional user status code that can provide more information about the status to operations personnel |
workflow_instance.status_sessionid | When the workflow order data instance is being processed, this value will be set to the session ID of the Qorus application instance session processing it. |
workflow_instance.scheduled | The earliest date and time the order can start processing; this date/time value is only used when the order's status is OMQ::StatReady |
workflow_instance.priority | The priority for the order; lower numbers equal higher priorities; priority numbers may be from 0 (the highest priority) to 999 (the lowest priority) |
workflow_instance.started | The time and date the workflow order data instance was initially processed. |
workflow_instance.completed | The time and date processing was completed for the workflow order data instance. |
workflow_instance.parent_workflow_instanceid | For subworkflows, this points to the parent workflow order data instance ID. |
workflow_instance.synchronous | For order data being processed synchronously, this flag will be set to 1 (= true). |
workflow_instance.business_error | Flag indicating if the workflow order data instance has an OMQ::StatError status due to a business error (if not set, the error status is due to a technical error). The interpretation of this flag depends on the order being processed, however normally the business error flag is set when the input data are inconsistent with the order to be processed (for example, the input data fail business validation rules) |
order_instance.external_order_instanceid | An optional external identifier for the workflow order data instance |
order_instance.staticdata | The initial order data – this cannot be changed by workflow execution instances that process it |
order_instance.dynamicdata | This is persistent data associated with the workflow order data instance. Any data stored here will remain until deleted from the DB. |
| User Keys | Optional key-value pairs attached to a workflow order data instanstaticce to be used in searching for the data |
Qorus has been designed to handle workflow order sensitive data with special APIs, encrypted storage, and carefully audited processing to avoid logging such data by the system itself and to ensure the security of such data from unauthorized access or inadvertent disclosure.
Workflow sensitive data can only be submitted with a new workflow order over a secure network interface (i.e. using an HTTPS listener); it's not possible to submit sensitive data over an unencrypted listener using system APIs.
Workflow order sensitive data is stored separately for each data subject against the workflow order using two identifiers (in addition to the workflow_instanceid designating the workflow order); within the order, each data subject's sensitive data is identified with the following keys:
skey: the sensitive data key type (not treated as sensitive itself; ex: "social_insurance_nr")svalue: the sensitive data key value, which is also treated as sensitive itselfThe value of skey must be decided in advance when designing an interface that will process sensitive data. This value is meant to describe the type of value stored in svalue. For example, if the sensitive data identifier is a social insurance number, then skey might be "social_insurance_nr" and svalue will be the social insurance number for the data subject (the natural person whose data are being processed).
The following image gives an overview of how sensitive data is stored against a workflow order:

In another example, an interface might identify data subjects with their tax number, so skey might be "tax_id", and svalue will be the tax number of the data subject.
The following image provides an overview of a concrete example of sensitive data stored against a workflow order storing sensitive data for at least two data subjects with tax_ids "984.302192.AF" and "739.323.714.BR":

In the above example, the sensitive key values ("984.302192.AF" and "739.323.714.BR") are encrypted when stored, additionally the sensitive data and metadata hashes for each data subject are also stored encrypted in the system database.
For each set of personal data stored in a workflow order, the two values skey and svalue identify sensitive data for a data subject and must be used for external queries or manipulation of sensitive data.
This data can be queried, updated, and deleted separately for each workflow order or for each data subject.
If another identifier for the customer is used, such as an internal account number (which might be used to ensure a common identifier for all sensitive data stored by an organization), then the skey value might be "account_nr", and svalue will be the organization's account number. In any case, svalue values will be treated as sensitive themselves, therefore they will not be logged in decoded form and also can only be sent or received over encrypted network links (at least when the system is aware that sensitive data is being sent or received as a part of system APIs designed to support this implementation).
Sensitive data APIs for workflows also support the possibility of creating internal aliases for sensitive data key/value pairs to allow sensitive data to be matched to cleartext workflow order data (such as Workflow Static Order Data or Workflow Dynamic Order Data); sensitive data aliases are not considered sensitive themselves and therefore should not be created using sensitive identifiers that can be used to determine the identity of the data subject.
The following REST APIs support sensitive data processing:
The following RBAC permissions allow operations on sensitive data to be restricted:
Only the system superuser role is allowed to create, retrieve, update, and delete sensitive data by default. Other roles must be updated with the appropriate permissions before they can access sensitive data from external interfaces.
The following system options support sensitive data processing:
If either of the sensitive data purge options is False, then sensitive data should be purged periodically from the system and archiving schemas using the qorus-sensitive-data job.
Notes can be added to a workflow order through internal and external APIs. These notes are stored in the ORDER_INSTANCE_NOTES table.
Notes are meant to be records of operational information about the processing or troubleshooting of an order. Notes can also be created in the web UI and are displayed there with the order instance data.
The following external APIs are related to notes:
The following internal APIs are related to notes:
As an order is being processed, it will have one or more segment rows created for it. This information is stored in the SEGMENT_INSTANCE table, which is an instantiation of Segment Metadata.
Segment Instance Attributes (table: SEGMENT_INSTANCE)
| Attribute | Description |
workflow_instanceid | The workflow order data instance that the segment instance belongs to |
segmentid | The metadata ID of the segment, unique in the workflow order data instance; the first segment has segmentid 0 |
segmentstatus | Segments can have any of the statuses in Workflow, Segment, and Step Status Descriptions except OMQ::StatIncomplete, OMQ::StatCanceled, and OMQ::StatBlocked |
custom_status | Segments can have an optional user status code that can provide more information about the status to operations personnel |
retry_trigger | When a segment has status OMQ::StatRetry or OMQ::StatAsyncWaiting, it can have a specific retry time set so that the retry occurs at this certain time, overriding system options qorus.recover_delay or qorus.async_delay |
Note that the retry_trigger value is set for a segment instance when a step requests a specific retry time; a specific retry time can be set by a step any time the step gets an OMQ::StatRetry or OMQ::StatAsyncWaiting status. In this case, the earliest retry time will take effect for the segment instance.
Each step that is executed for an order has a row in the STEP_INSTANCE table associated with it, which is an instantiation of Step Metadata.
Step Instance Attributes (table: STEP_INSTANCE)
| Attribute | Description |
workflow_instanceid | The workflow order data instance that the step instance belongs to (see Workflow Primary Order Instance Data) |
stepid | The metadata step ID for the step (see Step Metadata) |
ind | The array step index; the first element is always 0. Non-array steps will only have one STEP_INSTANCE entry for their stepid and this attribute will always set to 0 |
stepstatus | Steps can have any of the statuses in Workflow, Segment, and Step Status Descriptions except OMQ::StatReady, OMQ::StatIncomplete, OMQ::StatCanceled, and OMQ::StatBlocked |
custom_status | Steps can have an optional user status code that can provide more information about the status to operations personnel |
skip | This flag is set on steps that were skipped |
Additional tables of interest are:
QUEUE_DATA: where asynchronous messages are stored to be delivered to back-end code for asynchronous stepsSTEP_INSTANCE_EVENTS: where the event type and event key information is stored for steps pending on a workflow synchronization eventSUBWORKFLOW_INSTANCE: where the information is stored linking a step in a parent workflow to a child or sub workflowWORKFLOW_EVENTS: where workflow events are stored, holding the key value and posted statusThis section describes workflow execution instance processing.
The workflow startup procedures (SQL select statements) are split into batches due the performance reasons. It means that all steps described below are performend 1..N times depending on amount of data in the system database schema.
Size of these batches can be set by options:
Step 1: Open Log Files
When the first execution instance of a workflow starts, the workflow's shared log files are opened (and created if necessary) in append mode. Note that all workflow execution instances of the same type will normally share the same log file (depending on the file name mask). See System, Service, Workflow, and Job Logging for more information about logging.
Step 2: Execute One-Time Initialization
When a workflow execution instance is started, if any one-time initialization function has been defined, then this function will be executed. If any errors occur when running this function, then the workflow execution instance will fail to start.
Step 3: Start Segment Threads
Segments are groups of steps in a workflow separated by asynchronous or subworkflow steps. Two threads are started for each segment, one in OMQ::WM_Normal mode, and one in OMQ::WM_Recovery mode. Each segment thread is capable of processing a different workflow order data instance; in this sense segments run independently within the workflow execution instance.
OMQ::WM_Normal segments process workflow order data instances that are running without errors. Initial segments have segment ID 0 within a workflow and are always the first segments to be run.
When a workflow is started, the system event WORKFLOW_START is raised.
Note that in addition to the logic documented above, if the workflow execution instance is the first one of its workflow type to start executing, then background threads begin reading in workflow event data from the database as well.
In OMQ::WM_Normal mode the initial segment waits for new workflow order data instances to be submitted through the system API.
When this data is found, the workflow order data instance row is marked OMQ::StatInProgress and the segment instance row for segment ID 0 is created.
Asynchronous segments are segments that are separated from the previous segment by an asynchronous step.
Non-recovery (OMQ::WM_Normal) asynchronous segment threads wait for data to become available for the back end of the asynchronous step that separates the segment from its predecessor. The segment thread will be notified when a row in the QUEUE_DATA table with the asynchronous step's ID is updated with status OMQ::QS_Received. At this point, the data will be extracted from the row, the row is deleted, and the asynchronous back end is executed, with the queue data passed as an argument to the back-end code.
If the back-end code completes without an error, then the previous segment status is set to OMQ::StatComplete and the new segment is started (a row is inserted in the SEGMENT_INSTANCE table with status OMQ::StatInProgress).
Otherwise, if the back-end code throws an error, the new segment will not be started (and no SEGMENT_INSTANCE row will be created for it), and the asynchronous step's and front-end segment status will be set to reflect the error's status (either OMQ::StatError or OMQ::StatRetry).
Subworkflow segments are separated from the previous segment by a subworkflow step.
Non-recovery (OMQ::WM_Normal) subworkflow segments wait for a subworkflow order data instance (a normal workflow order data instance linked to a subworkflow step through the SUBWORKFLOW_INSTANCE table) linked to the subworkflow step to reach a OMQ::StatComplete status. When this happens, the new segment is started immediately. The parent step's status is also updated if a subworkflow bound to the step receives an OMQ::StatError status. OMQ::StatError statuses are propagated up through all parent workflow order data instances in case the workflow order data instance is a subworkflow itself.
Workflow synchronization event segments are separated from the previous segment by a workflow synchronization event step.
Non-recovery (OMQ::WM_Normal) workflow synchronization event segments wait for the dependent workflow event(s) (the segment can depend on more than one event if it is also an array step) to post and therefore the associated steps will receive a OMQ::StatComplete status. When this happens, the new segment is started immediately.
Recovery (OMQ::WM_Recovery) segments process segments with a OMQ::StatRetry or OMQ::StatAsyncWaiting status.
Recovery segments wait for a SEGMENT_INSTANCE row to become available meeting at least one of the following criteria:
Please note that system options for retry processing can be overridden at several levels listed here in order of priority (listed first equals highest priority):
When at least one of these criteria is true for a segment, the segment status is set to IN-PROGRESS, and steps without a status of OMQ::StatComplete are executed in their dependency order.
Steps that have already been executed at least once are subject to special processing. Before the step is executed, if validation code exists, the validation code is executed.
If the validation code raises an error, the step's status is set to the error's status.
If the validation code returns a status code, the status code is taken for the step's status (for example, COMPLETE will set the step immediately to COMPLETE without executing the primary step logic, RETRY will run the step's primary logic again, etc).
Array steps are executed like normal steps with the following exceptions: before an array step is executed, the array code is executed. The array code must return a list (an array), which will define how many times the primary step logic is executed.
If the array code returns NOTHING or a list with no elements, a single STEP_INSTANCE row will be created and the step will be marked as OMQ::StatComplete and processing will continue normally.
The array step will continue executing even if some elements return ERROR or RETRY statuses until all elements of the array have been iterated.
For array steps that are subworkflow or asynchronous steps, the segment linked to the back end (for asynchronous steps) or the subworkflow completion will only be started once all elements of the array step are OMQ::StatComplete.
When a step raises an error, the handling depends on how the error was defined by the workflow's error function (if any).
If the error has a severity less than OMQ::ES_Major, then the error is treated as a warning. See below for valid error statuses. Otherwise, the status of the error is taken as the status of the step (must be either ERROR, the default, or RETRY).
If an error was not defined by the workflow's error function, then the severity is by default MAJOR and the status ERROR.
Error Severity Levels
| Level | Description |
| OMQ::ES_Fatal | Indicates that the workflow execution instance should shutdown. |
| OMQ::ES_Major | Indicates that the workflow order data instance will be set to the error status of the error. |
| OMQ::ES_Minor | Indicates that the error will be logged but no other action will take place. |
When a workflow execution instance raises an error, the system event WORKFLOW_DATA_ERROR is raised.
When a workflow execution instance shuts down, all running segments must terminate first. In order for a running segment to terminate, it must complete processing of any steps that may be in progress. Therefore a long-running step can delay the workflow execution instance's shutdown.
After all running segments have terminated, the log file descriptor is closed, and the internal workflow execution instance object is deleted.
When a workflow is stopped, the system event WORKFLOW_STOP is raised.
Workflow order data instances are cached (remain in main system memory) for the number of seconds defined by the value of the qorus.detach-delay system option, if processing is halted with any status other that COMPLETE, ERROR, CAMCELED, or BLOCKED (and the cache is not full as determined by the qorus.cache-max system option).
This is designed to reduce database overhead for recoveries, asynchronous, workflow synchronization event, and subworkflow event processing. Without this option, the workflow order data instance would be purged immediately, and then when an asynchronous step's back end completes, or a subworkflow completes, the system would always have to read back in and parse the workflow's data form the database, incurring additional I/O that can be spared if the data is cached.
As mentioned above, the two system options that control Qorus' use of the workflow data cache are as follows:
When workflow metadata is reset by a call to the system API PUT /api/latest/workflows/{id_or_name}?action=reset (or omq.system.reset-workflow()) or PUT /api/latest/workflows?action=resetAll (or omq.system.reset-all-workflows()), the system event WORKFLOW_CACHE_RESET is raised.