|
Qorus Integration Engine® Enterprise Edition 7.0.7_prod
|
|
Qorus Integration Engine® Enterprise Edition 7.0.7_prod
|
Back to the Developer's Guide Table of Contents
All Qorus integration objects are described by YAML metadata produced by our IDE, which is available as a free (as in free of charge and also open source) extension to Microsoft Visual Studio Code, a multi-platform editor from Microsoft. The Qorus extension is called Qorus Developer Tools and can be installed directly from Visual Studio Code.
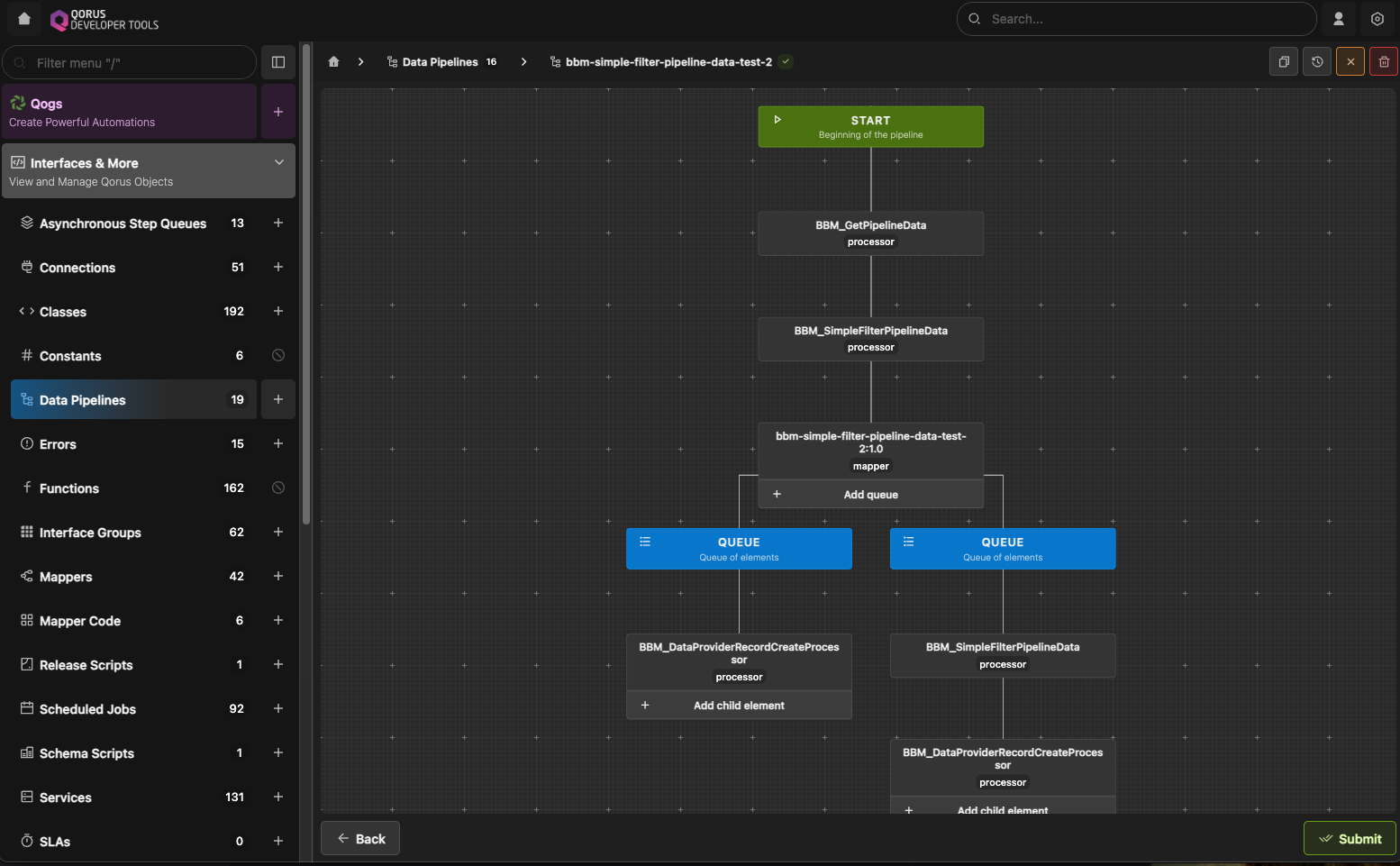
Data pipelines allow for complex and efficient processing of record-based data from a single input to an arbitrary number of outputs in an arbitrary number of processing queues.
Data pipelines by default have a single processing queue (with queue ID 0); to split processing of a single input, the last element of a queue can be a list of queues, each of which taking the data record(s) and processing them in parallel with other queues at the same level.
Besides the final element of a pipeline, which can be a series of queues for onwards parallel processing, each queue is a set of linear elements that takes data record input and outputs zero or more records to the next element in the pipeline. Pipeline elements can:
Note that all of the above operations can be performed at the same time on any given input record.
Pipeline processing elements are made up of objects of the following types:
In fact a mapper is a specialized configuration-driven form of a processor that does data format conversions.
Data pipelines can process input data in one of three ways:
$local:input when resolving factory options with UserApi::expandTemplatedValue().A data pipeline processor is a Qorus class object defined as a data processor (see Class Processor for more information).
Bulk processing is when a data pipeline processor is capable of processing data in "hash of lists" form. This format is the most efficient way to process many records of data in a single operation which results in very fast and efficient processing for large amounts of data.